Previsão do tempo de Natal-RN utilizando LSTM — Parte 2/3
Coleta e tratamento dos dados
Dando seguimento ao projeto, nesse artigo irei abordar sobre a coleta dos dados e o tratamento realizado sobre os mesmos.
Caso não tenha lido a parte 1, clique aqui.
Fonte dos dados
Desde o último trabalho sobre previsão do tempo, o Instituto Nacional de Meteorologia atualizou o seu site. Agora é possível baixar de forma mais rápida e prática os dados históricos anuais. Até o momento são 21 arquivos zip com dados de 2000 a 30 de setembro de 2020, um para cada ano.
Cada arquivo zip contêm vários arquivos CSV, um para cada estação que realizou alguma medição naquele ano. Após baixado todos os arquivos, criou-se um único arquivo CSV com os dados de todas as estações envolvidas por ano, além de renomear as colunas em cada arquivo para um determinado padrão e adicionando uma coluna para identificar a estação que coletou aqueles dados.
Os dados
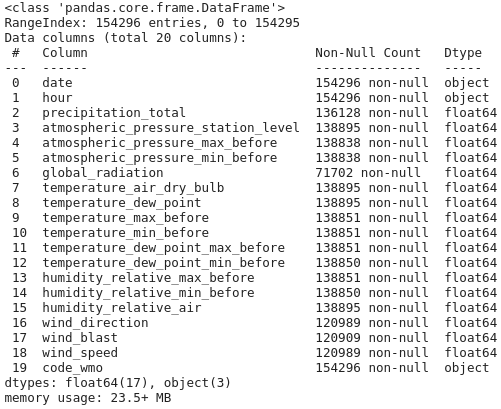
Os dados de cada ano foram agrupados em um único arquivo, totalizando 21 arquivos CSV, quase 6 GB de dados no total. São dados de medição por dia, hora e estação envolvida.
Todos os arquivos possuem um total de 20 colunas, sendo elas:
- date: data da coleta do dado (dia, mês e ano);
- hour: horário da coleta do dado (hora e minuto);
- precipitation_total: precipitação total, no horário (mm);
- atmospheric_pressure_station_level: pressão atmosférica ao nível da estação, no horário (mB);
- atmospheric_pressure_max_before: pressão atmosférica máxima na hora anterior (mB);
- atmospheric_pressure_min_before: pressão atmosférica mínima na hora anterior (mB);
- global_radiation: radiação global (KJ/m²);
- temperature_air_dry_bulb: temperatura do ar do bulbo seco, no horário (ºC);
- temperature_dew_point: temperatura do ponto de orvalho (ºC);
- temperature_max_before: temperatura máxima na hora anterior (ºC);
- temperature_min_before: temperatura mínima na hora anterior (ºC);
- temperature_dew_point_max_before: temperatura máxima do ponto de orvalho (ºC);
- temperature_dew_point_min_before: temperatura mínima do ponto de orvalho (ºC);
- humidity_relative_max_before: umidade relativa máxima na hora anterior (%);
- humidity_relative_min_before: umidade relativa mínima na hora anterior (%);
- humidity_relative_air: umidade relativa do ar, no horário (%);
- wind_direction: direção do vento (gr) (°(gr));
- wind_blast: rajada máxima do vento (m/s);
- wind_speed: velocidade do vento, no horário (m/s);
- code_wmo: código WMO da estação.
Dessas colunas, a nossa coluna alvo para previsão será temperature_air_dry_bulb.
Estação de Natal-RN
Como estamos querendo prever o tempo em Natal-RN, decidiu-se filtrar os dados para apenas as medições realizadas nas estações correspondentes. Os dados de Natal são:
- Região: Nordeste (NE);
- Estado: Rio Grande do Norte (RN);
- Cidade: Natal;
- Código (WMO): A304;
- Latitude: -5.9;
- Longitude: -35.2;
- Altitude: 48.6;
- Data de fundação: 24/02/2003.
A nossa extensão de dados vai de 24/02/2003 até 30/09/2020, possuindo um total de 154296 linhas no CSV gerado apenas com entradas de Natal-RN.
Tratamento
Durante o processamento, dados lixo (letras em colunas numéricas, NaN, etc) foram transformados em np.nan, para ficar mais fácil de identificar. Logo, realizou-se uma limpeza eliminando esses dados.
Após isso, selecionou-se apenas dados de 2017 em diante, totalizando 12018 linhas. O principal motivo disso é que os dados lixos eliminados anteriormente correspondiam a dados dos primeiros anos. Assim os dados com “maior qualidade” estavam nos anos mais recentes.
Como as colunas date e hour são de objetos, decidiu-se criar novas colunas a partir delas para manipulações posteriores, sendo essas novas colunas:
- day: o dia do registro;
- month: o mês do registro;
- year: o ano do registro;
- week: a semana do ano do registro;
- day_week: o dia da semana do registro;
- hour: a hora do registro (diferente da coluna hour anterior, essa daqui possui apenas a hora).
Dados para treinamento
Depois do tratamento realizado nos dados, foi analisado a correlação das colunas com nossa coluna alvo (temperature_air_dry_bulb) e selecionada as colunas com correlação de Pearson maior que 0.5 ou menor que -0.5.

Ao final restou-se apenas 7 colunas além da nossa coluna alvo:
- humidity_relative_air: -0.759900;
- humidity_relative_min_before: -0.753720;
- humidity_relative_max_before: -0.709979;
- wind_direction: -0.547639;
- global_radiation: 0.698207;
- temperature_min_before: 0.950094;
- temperature_max_before: 0.971995.

Uma coisa que achei interessante foi que as colunas com maior correlação eram justamente as que se referiam aos valores mínimo e máximo da temperatura na hora anterior a medição.
Para todos os treinamentos foram utilizados as seguintes proporções:
- 90% dos dados para treino;
- 10% dos dados para teste.
Nota de esclarecimento
O principal motivo de todo esse tratamento e seleção dos dados, além de ser para garantir a qualidade dos mesmos, foi por causa do tempo que estava levando para realizar o treinamento do modelo, chegando a dias. Com os dados selecionados e tratados, o treinamento passou para, em média, 6 horas para cada modelo.
Código
- Baixar e transformar os arquivos CSV: https://github.com/alvarofpp/dataset-inmet
- Limpeza e tratamento dos dados: https://github.com/alvarofpp/imd1104-weather-forecasting
Esse artigo foi escrito para a disciplina de Aprendizado Profundo do curso de Bacharelado em Tecnologia da Informação (BTI) da Universidade Federal do Rio Grande do Norte (UFRN), possuindo Ivanovitch Silva como professor.










